En la facultad de Ciencias Exactas y Naturales de la Universidad de Buenos Aires existen concursos docentes. Para conseguir un cargo los aspirantes luego de juntar ciertos requisitos compiten contra otros candidatos. El concurso se basa en cuantificar distintas categorías de la experiencia del aspirante (antecedentes docentes, de extensión, científicos, calificaciones, etc) y una prueba de oposición donde el concursante debe performar alguna tarea establecida por el jurado. Dependiendo del cargo que se concursa dicha tarea va desde presentar la resolución de un ejercicio hasta presentar el plan de práctica de una materia.
El cargo de ayudante de 2da tiene dos particularidades: los aspirantes deben ser alumnos y la duración del cargo es de 1 año por lo que para sostener el mismo deben concursar anualmente. En el departamento de computación los concursos están separados en 3 áreas con aproximadamente 45 cargos regulares en total. En el 2015 quedaron los distintos órdenes de mérito aproximadamente 140 personas. Teniendo en cuenta que la prueba de oposición más la discusión del jurado dura al menos 15-20 minutos y que en cada concurso hay 3 jurados, se dedicaron entre 100 y 140 hs hombre (sin contar el extenso trabajo previo de cuantificar los antecedentes), 3.5 semanas laborables completas (40 hs semanales).
Como la información de los concursos es pública nos preguntamos si existe alguna regularidad en los dictámenes entre aspirantes y año tras año.
Distribución en el orden de mérito de concursantes con y sin experiencia en concursos previos.

Tomando como ejemplo el concurso de ayudante de 2da área algoritmos para 2013, 2014 y 2015 se puede medir cómo se distribuye el orden de mérito en función a si el concursante tiene experiencia en concursos del área o concursa por primera vez. En principio las tasas de concursantes nuevos, es decir sin experiencia, es la siguiente:
Año
|
Tasa de concursantes sin experiencia
|
2013
|
0.3606
|
2014
|
0.5571
|
2015
|
0.4492
|
Teniendo en cuenta esto y que dicho concurso hay 20 cargos podemos separar el orden de mérito en los que obtienen un cargo regular (los primeros 20) y los que no (desde la posición 21 en adelante). Cabe aclarar que después terminan obteniendo cargo más aspirantes ya sea por renuncias o por nominaciones interinas.
Los nuevos candidatos se distribuyen muy distinto en los dos grupos (los que obtienen cargo vs los que no) acorde a lo esperado.
Sobre aspirantes sin experiencia
| ||
Obtuvieron cargo
|
No obtuvieron cargo
| |
2013
|
12%
|
88%
|
2014
|
10%
|
90%
|
2015
|
14%
|
86%
|
Esto confirma lo esperado, ingresantes nuevos se distribuyen no uniformemente quedando más atrás en el orden de méritos de los concursos.
¿Somos consistentes en el tiempo? ¿Mejoramos?
Otra pregunta que nos preguntamos fue si existe una correlación en cada aspirante entre concursos consecutivos. Es decir, si en el 2013 un concursante salio ultimo ¿Es esperable que en el siguiente salga primero? Si otro salió 5to en el 2013 ¿Es esperable que salga en la posición 70 en el 2014? Para contestar esto armamos la relación <posicion concurso anterior, posición concurso actual> para todos los sujetos (a su vez armamos la misma relación pero normalizando la posición en el concurso por la cantidad de concursantes)
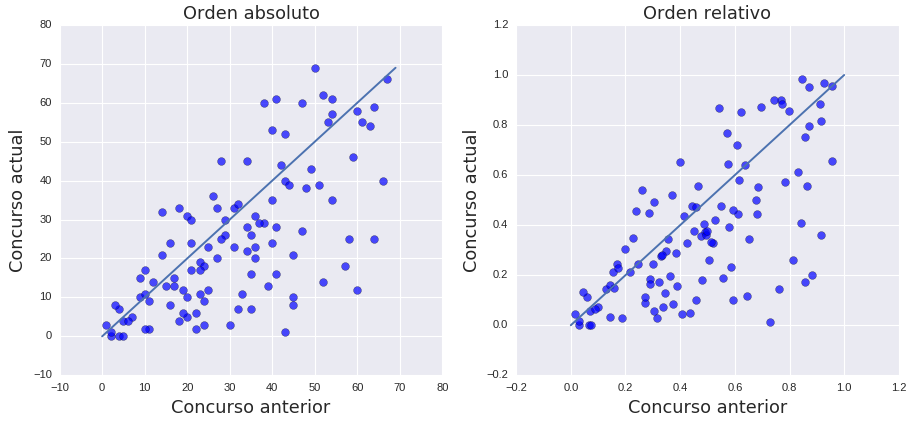
Los datos muestran que existe una correlación positiva (pearson rho >0.68, pval<10^-15) indicando que se mantiene cierto orden en el tiempo. Esto significa que si en un un concurso un aspirante quedó en la posición 10 es en el próximo probablemente quede cerca de la misma posición y lo mismo ocurriría para aquel que quedó al final del orden. Sin embargo, si bien el comportamiento tiene esta pinta también muestra que los aspirantes mejoran con el tiempo (más antecedentes y/o mejoran en la prueba de oposición) . De hecho la recta que mejor fitea los datos de ay2 algoritmos tiene es:
posicion_nuevo_concurso = posicion_concurso_anterior * .72 + 1.98
Suponiendo que tenemos 70 inscriptos en el concurso constantemente para los dos años.
Si en el 2013 un aspirante salió en la posición 60 (osea casi a lo último), este modelo predice que en el 2014 el mismo aspirante saldrá (o salió) en la posición 45. Si otro salió, en el 2013, en la posición 20 el modelo propone que en el 2014 el aspirante saldría en la posición 16/17.
Para testear la validez de este “modelo” performamos validación cruzada de 5 folds reportando un r^2 promedio es 0.46 con una varianza de 0.07.
Para analizar cómo mejoran los concursantes en el tiempo, tomamos todos los aspirantes a concursos de ayudante de 2da con 4 concursos en el mismo área (15).

Tomando la media por concurso por sujeto podemos caracterizar la curva promedio de mejora donde se aprecia lo esperado, inicialmente mejoramos rápidamente y luego disminuye la velocidad, lo que es esperable pues el top10 del ranking tiene mucho menos rango que las últimas 10 posiciones.
Automatización de orden de mérito
Dada las regularidades que ya reportamos nos preguntamos que resultaría de ordenar los aspirantes automáticamente.
La primera prueba que hicimos fue preguntarnos cómo nos va seleccionando a los ganadores. Para eso definimos la siguiente estrategia: Tomamos la lista de aspirante del concurso actual sin orden e intersecamos con la lista con el concurso anterior respetando el orden del concurso anterior. Devolvemos como nuevo orden esta lista y luego los restantes en cualquier orden. Esta idea trivial genera los siguiente resultados para los concursos de ayudante de 2da algoritmos.
Sobre los 20 ganadores
| ||
Año
|
Precisión
|
Chance
|
2013
|
65%
|
28%+-4%
|
2014
|
60%
|
29%+-4%
|
2015
|
80%
|
33%+-4%
|
Los valores de chance son los obtenidos al comparar nuestra estrategia con distintos órdenes al azar. Esta comparación la reportamos para tener idea de cuán bien funciona nuestra estrategia.
La siguiente prueba que hicimos fue intentar regresionar la posición de cada concursante en el orden de mérito. Para eso enriquecimos un poco más cada aspirante con los siguientes atributos:
- Cantidad de concursos anteriores (en cualquier área)
- Si ya concurso como ayudante de primera
- La media en las posiciones relativas en concursos anteriores
- El desvío estándar en la posición relativa en concursos anteriores
- La media de la derivada de las posiciones relativas en concursos anteriores
- La posición en el concurso inmediatamente anterior
Tomando estos atributos haciendo una regresión no lineal en el mismo esquema de validación cruzada de 5 folds obtenemos un r^2 de 0.6145, mucho mejor que con el modelo lineal y más simple.
En resumen, tener bien formateados los datos para hacer análisis de este tipo puede resultar interesante. Lamentablemente no contábamos con los valores para cada categoría del concurso (antecedentes docentes, extensión, etc…) , con esto podría haberse estudiando el efecto de sobre ajustar la performance de la prueba de oposición al jurado, práctica que se ejerce comúnmente. A su vez, estudiar el sesgo que ponen los jurados al usar distintos rangos para cada categoría.
Algunas ideas de que mirar y cómo medirlo fueron pensadas y discutidas con Edgar Altszyler
Algunas ideas de que mirar y cómo medirlo fueron pensadas y discutidas con Edgar Altszyler
















{kind=link}